
本文聚焦于爬取各国疫情数据这一主题,深入探讨在数据爬取过程中,技术层面背后所蕴含的故事以及所面临的重重挑战。
最近这几年,疫情成了咱们生活中绕不开的话题,每天打开手机,新闻里、社交媒体上,到处都是关于疫情的最新消息,而在这背后,有一群技术大神,他们通过爬取各国疫情数据,为我们提供了及时、准确的信息,咱们就来聊聊这个话题,看看爬取各国疫情数据到底是怎么回事,又面临着哪些挑战。
先说说啥是爬取数据吧,爬取数据就是利用计算机程序,自动从网页上抓取我们需要的信息,就像咱们平时在网上搜索东西,浏览器会帮咱们把相关的网页内容展示出来一样,爬虫程序也能做到这一点,只不过它是自动化的,而且能抓取大量的数据。
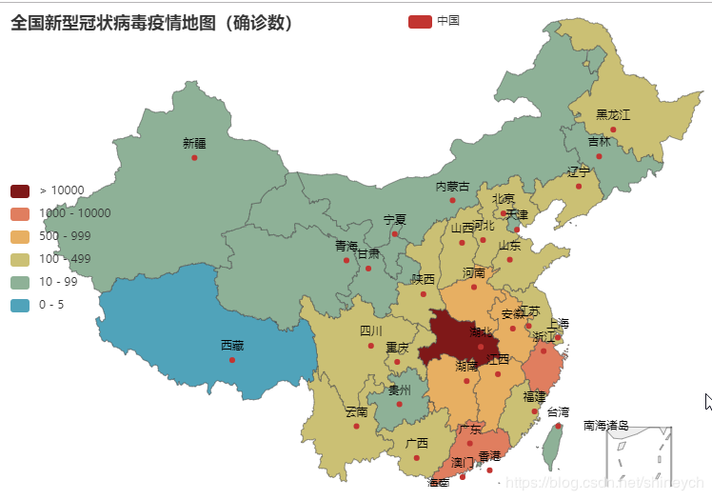
在疫情期间,爬取各国疫情数据变得尤为重要,因为疫情数据是动态变化的,每天都有新的确诊病例、死亡病例、治愈病例等数据更新,如果靠人工去一个个网站查看、记录,那效率太低了,而且容易出错,而爬虫程序就能很好地解决这个问题,它能定时、自动地抓取各国疫情数据,然后整理成我们需要的格式,比如表格、图表等,方便我们查看和分析。
爬取各国疫情数据具体是怎么操作的呢?这个过程并不复杂,但也需要一定的技术基础,得确定要爬取哪些网站的数据,各国卫生部门、疾控中心或者权威的新闻媒体网站都会发布疫情数据,编写爬虫程序,让它按照设定的规则去抓取这些网站上的数据,在编写程序的时候,得注意一些细节,比如设置合适的请求头,避免被网站的反爬虫机制拦截;还要处理可能出现的异常情况,比如网络连接失败、页面结构变化等。
爬取到数据之后,接下来就是数据的清洗和整理了,因为从网页上抓取下来的数据往往包含很多无关的信息,比如广告、导航栏等,这些都需要去掉,还得把数据转换成统一的格式,方便后续的分析和展示,把日期转换成标准的格式,把数字转换成整数或浮点数等。
说到爬取各国疫情数据的挑战,那可真不少,就是网站的反爬虫机制,为了防止数据被恶意抓取,很多网站都会设置反爬虫机制,比如限制访问频率、要求登录验证等,这就要求爬虫程序得足够智能,能够绕过这些限制,或者模拟正常的用户行为进行访问。
就是数据的质量问题,虽然大部分网站都会发布准确的疫情数据,但也有一些网站的数据可能存在错误或者遗漏,这就需要我们在爬取数据之后,进行仔细的核对和验证,确保数据的准确性。
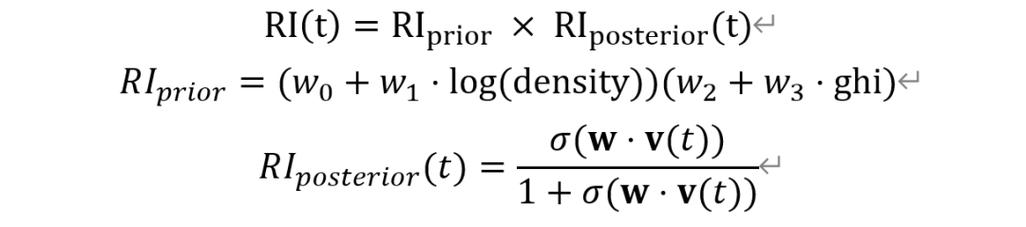
还有语言和文化差异的问题,不同国家的网站,使用的语言、编码方式、页面结构等都可能不同,这就要求爬虫程序得具备跨语言、跨文化的能力,能够适应不同网站的特点。
举个例子来说吧,有一次我尝试爬取某个小国的疫情数据,结果发现那个国家的网站用的是一种不太常见的语言编码,而且页面结构也很复杂,我花了不少时间才找到合适的方法来解析这个网站的数据,还有一次,我爬取的数据里包含了很多重复的记录,后来才发现是因为网站更新了页面结构,但我的爬虫程序没有及时调整导致的。
尽管面临着这么多挑战,但爬取各国疫情数据的工作还是非常有意义的,它不仅为我们提供了及时、准确的疫情信息,还帮助我们更好地了解疫情的发展趋势,为疫情防控提供了有力的支持。
随着技术的不断进步,爬取数据的方法也在不断改进,现在有很多开源的爬虫框架和工具,可以大大降低爬虫开发的难度,还有一些专门的数据清洗和整理工具,可以帮助我们更高效地处理爬取到的数据。
当然啦,爬取数据也得遵守相关的法律法规和道德规范,不能随意抓取他人的隐私信息,也不能对网站造成过大的负担,在爬取数据之前,最好先了解一下网站的使用条款和隐私政策,确保自己的行为是合法的。
爬取各国疫情数据是一项既有趣又有挑战性的工作,它让我们有机会深入了解疫情的发展情况,也让我们感受到了技术的力量,虽然过程中会遇到很多困难,但只要我们不断学习、不断尝试,就一定能够克服这些困难,为疫情防控贡献自己的一份力量。
我想说的是,疫情虽然给我们带来了很多不便和困扰,但也让我们更加珍惜生命、更加关注健康,希望疫情能够早日过去,我们的生活能够恢复正常,也感谢那些为爬取疫情数据付出努力的技术大神们,是你们的辛勤工作让我们能够及时了解疫情的最新情况。









发表评论